


自強課程

課程名稱
【竹科管理局線上補助課程】PyTorch生成式AI
如期開班
全線上
📢會員於7/13前(含)報名:
🥇園區內:500元/人;(二人同行👉免費)<煩請來電或來信告知同行者>。
🥈園區外:800元
<6/1起恢復原價,敬請把握!>
※任職於 【科學園區廠商】 優先錄取!
※早鳥優惠價統一於確定開課後修改金額!
🥇園區內:500元/人;(二人同行👉免費)<煩請來電或來信告知同行者>。
🥈園區外:800元
<6/1起恢復原價,敬請把握!>
※任職於 【科學園區廠商】 優先錄取!
※早鳥優惠價統一於確定開課後修改金額!
💥上課出席率需達75%哦❗💥
課程代碼:
14C345
上課時間:
7/20、7/27,星期日,10:00-17:00,共二週12小時。
※敬請留意:課程日期原定6/7(六)開課,因故已異動至7/20(日)開課。
※敬請留意:課程日期原定6/7(六)開課,因故已異動至7/20(日)開課。
上課時數:
12 小時
上課地點:
網路線上
課程費用:
(以下費用已由竹科管理局補助80%)
4000元
(科學園區廠商優惠價格需送出報名表後,系統發出報名成功回函確認金額。)
超值優惠:
課程目標:
近年來生成式AI技術的效果大幅進化,而這一切的起源來自2014 年Ian Goodfellow提出的生成式對抗網路(Generative Adversarial Network, GAN),過去這幾年,更新、更強大的GAN不斷地被提出,使得各種影像生成或是影像轉換等應用的效果愈來愈好,例如StyleGAN已經能生成極為真實的人臉影像,StarGAN可分別轉換人臉的髮型、年齡或膚色; AugGAN可將一張白天影像轉換成晚上、雨天甚至是雨天夜晚,而這可以幫助自動駕駛車辨識系統產生巨量各式各樣行車情境下的訓練資料,以提升辨識率。
目前生成模型的代名詞從GAN變成Diffusion model(擴散模型),且在各類任務上已經被證實效果比GAN更好,2022年StableDiffusion的橫空出世,讓我們可以用一段充滿細節的文字,生成極為真實的影像,此模型的主要原理來自同一年的LDM(Latent Diffusion Model),而Diffusion model的主要突破來自2020年的DDPM模型,LDM最主要的突破在於將denoising的過程實現在Latent vector而不是影像中,因而能大幅提升模型訓練以及推論的速度。本課程在Diffusion model將會介紹經典的DDPM(Denoising Diffusion Probabilistic Models), DDIM(Denoising Diffusion Implicit Models)以及LDM如何實現影像生成,Palette是如何運用Diffusion model實現影像轉換。
2022年底開始,如何微調Stable Diffusion成為了一門顯學,Stable Diffusion剛出現時為人所詬病的就是人物的手指往往很不自然,隨著Controlnet的出現,我們可以控制生成人物的姿態,以及自然的手部,甚至我們可以文字搭配素描/深度圖/光線分佈,來產生我們心目中的那張"圖"。
為了讓Stable Diffusion學會新的概念,我們還可以使用Dreambooth微調模型,但又不會讓強大的Stable Diffusion忘記特定的影像, LORA的出現讓微調Stable Diffusion的檔案小到幾個MB,我們只要找到公開的LORA檔案,我們也可以生成某個明星,例如"迪麗熱巴",的照片,甚至我們可以使用Textual Inversion的技術,產生特定概念的token,讓Stable Diffusion學會生成在某種場景下的某種特定物品(例如小時候爸媽送你的一個玩偶)。最後,Stable Diffusion只能透過文字產生影像,我們可否使用文字這樣的指令修改一張圖的內容呢?Instruct-Pix2Pix的出現告訴我們可以運用GPT模型所生成的文字來訓練生成模型實現影像編輯。
本課程具體內容包括:
(1)生成式對抗網路原理以及量化指標。
(2)基礎人臉影像生成模型: CGAN與DCGAN原理。
(3)進階人臉影像生成模型: ProGAN與StyleGAN。
(4)圖片分類以及人臉辨識:人臉辨識是圖片分類最重要的應用之一,運用softmax loss,Triplet loss以及ArcFace我們可較佳的實現人臉辨識。
(5)人臉合成: Image2StyleGAN原理以及如何運用人臉重建以完成人臉合成,並運用人臉辨識模型來分析合成人臉與原始人臉的相似度。
(6)擴散模型原理:如何運用DDPM/DDIM/LDM實現影像生成。
(7)Stable Diffusion及其四大微調技術: 運用Dreambooth/LORA/Textual Inversion微調強大的生成模型,以生成明星或是特定物品在新情境下的影像。
經過本次課程的洗禮,您將學會:
(1)從頭訓練一個生成模型網路
(2)在影像生成效果不佳時,如何尋找較佳的生成模型以生成更為真實的影像,(3)學會運用生成模型生成影像分類、語義分割、物件偵測所需要的訓練影像,以降低標記資料的需求。
目前生成模型的代名詞從GAN變成Diffusion model(擴散模型),且在各類任務上已經被證實效果比GAN更好,2022年StableDiffusion的橫空出世,讓我們可以用一段充滿細節的文字,生成極為真實的影像,此模型的主要原理來自同一年的LDM(Latent Diffusion Model),而Diffusion model的主要突破來自2020年的DDPM模型,LDM最主要的突破在於將denoising的過程實現在Latent vector而不是影像中,因而能大幅提升模型訓練以及推論的速度。本課程在Diffusion model將會介紹經典的DDPM(Denoising Diffusion Probabilistic Models), DDIM(Denoising Diffusion Implicit Models)以及LDM如何實現影像生成,Palette是如何運用Diffusion model實現影像轉換。
2022年底開始,如何微調Stable Diffusion成為了一門顯學,Stable Diffusion剛出現時為人所詬病的就是人物的手指往往很不自然,隨著Controlnet的出現,我們可以控制生成人物的姿態,以及自然的手部,甚至我們可以文字搭配素描/深度圖/光線分佈,來產生我們心目中的那張"圖"。
為了讓Stable Diffusion學會新的概念,我們還可以使用Dreambooth微調模型,但又不會讓強大的Stable Diffusion忘記特定的影像, LORA的出現讓微調Stable Diffusion的檔案小到幾個MB,我們只要找到公開的LORA檔案,我們也可以生成某個明星,例如"迪麗熱巴",的照片,甚至我們可以使用Textual Inversion的技術,產生特定概念的token,讓Stable Diffusion學會生成在某種場景下的某種特定物品(例如小時候爸媽送你的一個玩偶)。最後,Stable Diffusion只能透過文字產生影像,我們可否使用文字這樣的指令修改一張圖的內容呢?Instruct-Pix2Pix的出現告訴我們可以運用GPT模型所生成的文字來訓練生成模型實現影像編輯。
本課程具體內容包括:
(1)生成式對抗網路原理以及量化指標。
(2)基礎人臉影像生成模型: CGAN與DCGAN原理。
(3)進階人臉影像生成模型: ProGAN與StyleGAN。
(4)圖片分類以及人臉辨識:人臉辨識是圖片分類最重要的應用之一,運用softmax loss,Triplet loss以及ArcFace我們可較佳的實現人臉辨識。
(5)人臉合成: Image2StyleGAN原理以及如何運用人臉重建以完成人臉合成,並運用人臉辨識模型來分析合成人臉與原始人臉的相似度。
(6)擴散模型原理:如何運用DDPM/DDIM/LDM實現影像生成。
(7)Stable Diffusion及其四大微調技術: 運用Dreambooth/LORA/Textual Inversion微調強大的生成模型,以生成明星或是特定物品在新情境下的影像。
經過本次課程的洗禮,您將學會:
(1)從頭訓練一個生成模型網路
(2)在影像生成效果不佳時,如何尋找較佳的生成模型以生成更為真實的影像,(3)學會運用生成模型生成影像分類、語義分割、物件偵測所需要的訓練影像,以降低標記資料的需求。
課程大綱:
1.生成式對抗網路原理以及量化指標。
2.基礎人臉影像生成模型: CGAN與DCGAN原理。
3.進階人臉影像生成模型: ProGAN與StyleGAN。
4.人臉修改: Image2StyleGAN原理以及如何運用人臉重建以完成人臉修改。
5.圖片分類以及人臉辨識:人臉辨識是圖片分類最重要的應用之一,運用softmax loss,Triplet loss以及ArcFace我們可較佳的實現人臉辨識。
6.擴散模型原理:如何運用DDPM/DDIM/LDM實現影像生成。
7.Stable Diffusion及其四大微調技術: 運用Dreambooth/LORA/Textual Inversion微調強大的生成模型,以生成明星或是特定物品在新情境下的影像。
2.基礎人臉影像生成模型: CGAN與DCGAN原理。
3.進階人臉影像生成模型: ProGAN與StyleGAN。
4.人臉修改: Image2StyleGAN原理以及如何運用人臉重建以完成人臉修改。
5.圖片分類以及人臉辨識:人臉辨識是圖片分類最重要的應用之一,運用softmax loss,Triplet loss以及ArcFace我們可較佳的實現人臉辨識。
6.擴散模型原理:如何運用DDPM/DDIM/LDM實現影像生成。
7.Stable Diffusion及其四大微調技術: 運用Dreambooth/LORA/Textual Inversion微調強大的生成模型,以生成明星或是特定物品在新情境下的影像。
課程師資:
自強基金會 林老師
現任瑞典Chalmers University of Technology博士後研究員
經歷
▻ 工研院機械所副研究員/研究員/資深研究員
▻ 馬來西亞偉特科技公司(ViTrox)研發顧問
▻ 馬來西亞10 EPOCH科技公司研發顧問
▻ 加州大學聖塔芭芭拉分校資工系訪問研究員
專長
電腦視覺、機器學習、深度學習及其在駕駛輔助系統以及自駕車之各種應用
現任瑞典Chalmers University of Technology博士後研究員
經歷
▻ 工研院機械所副研究員/研究員/資深研究員
▻ 馬來西亞偉特科技公司(ViTrox)研發顧問
▻ 馬來西亞10 EPOCH科技公司研發顧問
▻ 加州大學聖塔芭芭拉分校資工系訪問研究員
專長
電腦視覺、機器學習、深度學習及其在駕駛輔助系統以及自駕車之各種應用
主辦單位:
財團法人自強工業科學基金會
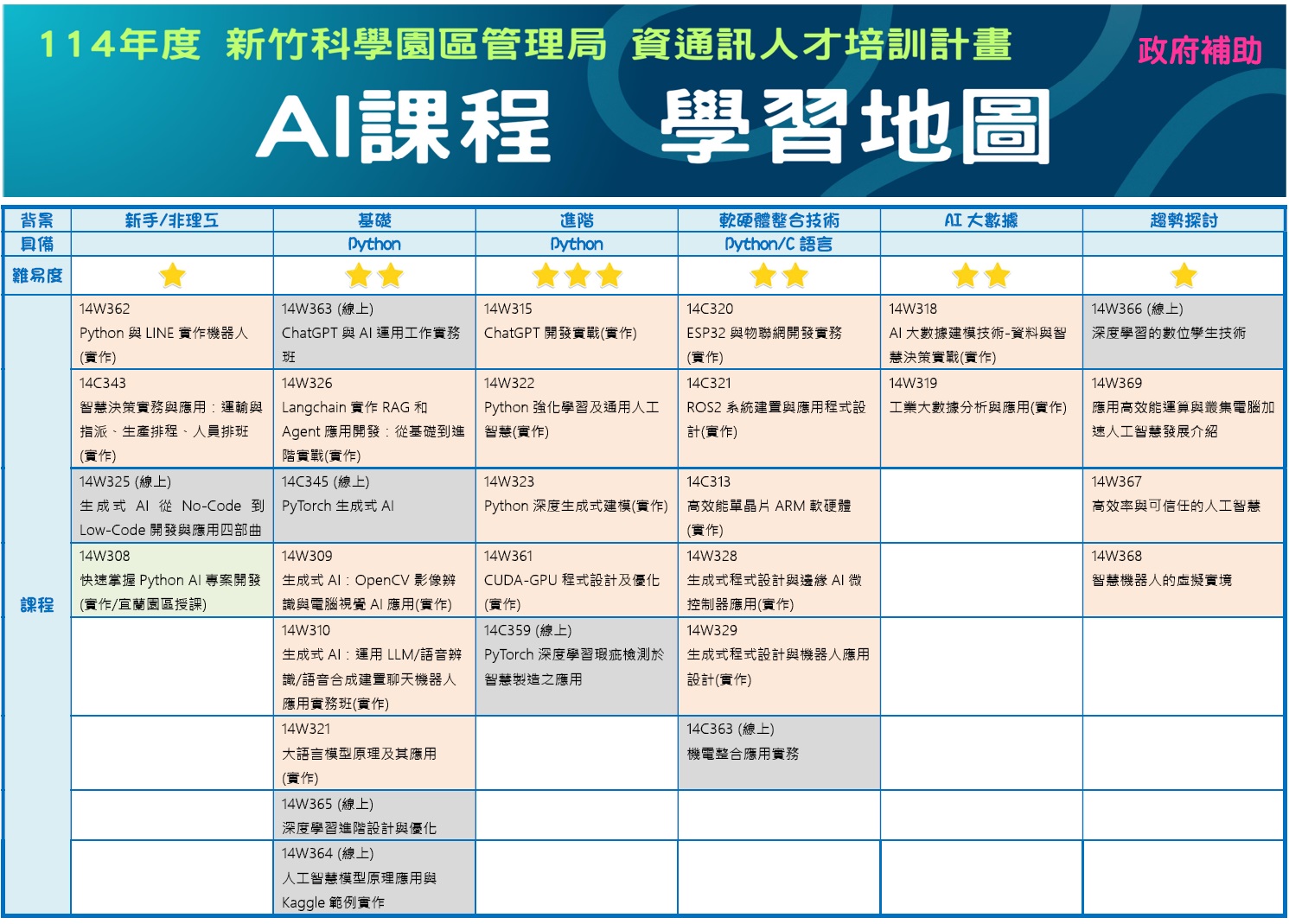
相關課程:
6月
14W319【竹科管理局補助課程】工業大數據分析與應用(6/3開班)
14W362【竹科管理局補助課程】Python與LINE實作機器人(實作) (6/7開班)
14W326【竹科管理局補助課程】Langchain實作RAG和Agent應用開發:從基礎到進階實戰 (6/8開班)
14C343【竹科管理局補助課程】智慧決策實務與應用:運輸與指派、生產排程、人員排班(實作) (6/10開班)
14W363【竹科管理局線上補助課程】ChatGPT與AI運用工作實務班(6/18開班)
14C320【竹科管理局補助課程】ESP32與物聯網開發實務(實作) (6/21開班)
14W309【竹科管理局補助課程】生成式AI:OpenCV 影像辨識與電腦視覺AI應用實作班 (6/22開班)
7月
14W310【竹科管理局補助課程】生成式AI:運用LLM/語音辨識/語音合成建置聊天機器人應用實務班(實作) (7/6開班)
14W321【竹科管理局補助課程】大語言模型原理及其應用(實作) (7/8開班)
14C321【竹科管理局補助課程】ROS2系統建置與應用程式設計(實作) (7/12開班)
14C313【竹科管理局補助課程】高效能單晶片ARM軟硬體(實作) (7/19開班)
14C345【竹科管理局線上補助課程】PyTorch生成式AI (7/20開班)
14W325【竹科管理局線上補助課程】生成式AI從No-Code到Low-Code開發與應用四部曲 (7/26開班)
14W319【竹科管理局補助課程】工業大數據分析與應用(6/3開班)
14W362【竹科管理局補助課程】Python與LINE實作機器人(實作) (6/7開班)
14W326【竹科管理局補助課程】Langchain實作RAG和Agent應用開發:從基礎到進階實戰 (6/8開班)
14C343【竹科管理局補助課程】智慧決策實務與應用:運輸與指派、生產排程、人員排班(實作) (6/10開班)
14W363【竹科管理局線上補助課程】ChatGPT與AI運用工作實務班(6/18開班)
14C320【竹科管理局補助課程】ESP32與物聯網開發實務(實作) (6/21開班)
14W309【竹科管理局補助課程】生成式AI:OpenCV 影像辨識與電腦視覺AI應用實作班 (6/22開班)
7月
14W310【竹科管理局補助課程】生成式AI:運用LLM/語音辨識/語音合成建置聊天機器人應用實務班(實作) (7/6開班)
14W321【竹科管理局補助課程】大語言模型原理及其應用(實作) (7/8開班)
14C321【竹科管理局補助課程】ROS2系統建置與應用程式設計(實作) (7/12開班)
14C313【竹科管理局補助課程】高效能單晶片ARM軟硬體(實作) (7/19開班)
14C345【竹科管理局線上補助課程】PyTorch生成式AI (7/20開班)
14W325【竹科管理局線上補助課程】生成式AI從No-Code到Low-Code開發與應用四部曲 (7/26開班)
學員須知:
注意事項
※請前往竹科管理局廠商與單位名錄進行查詢,即可判斷公司是否為園區內廠商。
- 本計畫鼓勵女性學員報名參加培訓課程,必要時得優先錄取。
- 本計畫以竹科園區事業單位從業員工為主優先錄取,若有名額將開放有志進入園區就業人士報名參加。
- 請學員填寫能收到紙本講義之有效地址(提供地址錯誤將不重寄紙本講義),已有提供電子講義下載之課程/講座將不另郵寄紙本講義。
- 若遇不可預測之突發因素,基金會保有相關課程調整、取消及講師之變動權。
- 無紙化環境,輕鬆達到減碳救地球,即日起16小時以上課程結業證書或未達16小時課程上課證明皆以電子方式提供。
- 本課程不適用廠商VIP折扣優惠
- 課前請詳閱簡章之課程內容或利用課程諮詢電話。
- 課程嚴禁旁聽,亦不可攜眷參與。
- 優惠方案擇一使用。
☆課程費用包含:紙本講義及稅。(不供午餐)
☆計畫補助課程不適用於其他基金會優惠方案及不可使用紅利點數折抵費用。
★計畫補助課程開課後,若因故無法上課,則不予退費。
✨針對園區廠商提供企業內訓課程規劃並享有優惠方案,若有需求可洽03-5623116分機3610鄒小姐。