


自強課程

課程名稱
【竹科管理局線上補助課程】生成式影像與多模態 AI:從 Diffusion 到視覺語言模型~📢區內免費
如期開班
全線上
✨補助優惠價:會員於7/22前(含)報名:✨
🥇園區內:免費。
🥈園區外:700元/人。
📌任職於【科學園區廠商】 優先錄取! 報名完成後將會由後端統一修改優惠金額。
<7/23起恢復原價,敬請把握!>
🥇園區內:免費。
🥈園區外:700元/人。
📌任職於【科學園區廠商】 優先錄取! 報名完成後將會由後端統一修改優惠金額。
<7/23起恢復原價,敬請把握!>
💥掌握生成模型、視覺語言與多模態實作,親手用 PyTorch 打造專屬 AI 影像與互動應用!💥
📌每位學員必須有自己的Google 帳號以在Colab進行實作
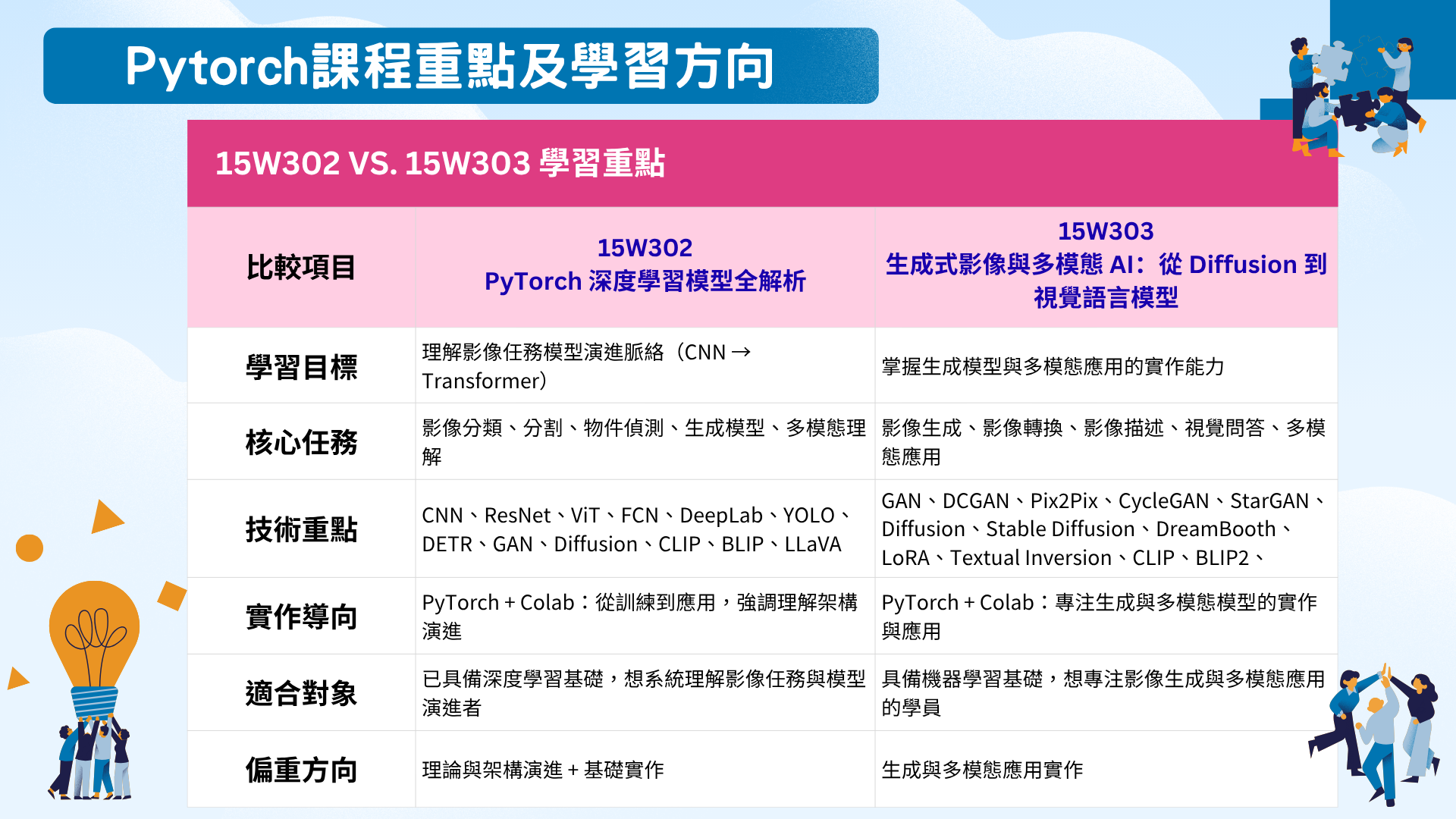
⭐若您想全面瞭解深度學習並涵蓋多種應用領域(分類、偵測、生成等)
🉑➡ 15W302【竹科管理局線上補助課程】PyTorch深度學習模型全解析(從CNN到Transformer) ⬅🤳請點課程
⭐若您想全面掌握生成模型與多模態應用的實作能力
🉑➡ 15W303【竹科管理局線上補助課程】生成式影像與多模態 AI:從 Diffusion 到視覺語言模型 ⬅🤳請點課程
💥上課出席率需達75%哦❗💥
🎁《優惠價》統一於確定開課後修改金額!
📌每位學員必須有自己的Google 帳號以在Colab進行實作
⭐若您想全面瞭解深度學習並涵蓋多種應用領域(分類、偵測、生成等)
🉑➡ 15W302【竹科管理局線上補助課程】PyTorch深度學習模型全解析(從CNN到Transformer) ⬅🤳請點課程
⭐若您想全面掌握生成模型與多模態應用的實作能力
🉑➡ 15W303【竹科管理局線上補助課程】生成式影像與多模態 AI:從 Diffusion 到視覺語言模型 ⬅🤳請點課程
💥上課出席率需達75%哦❗💥
🎁《優惠價》統一於確定開課後修改金額!
課程代碼:
15W303
上課時間:
7/26、8/2,星期日,10:00-17:00,共二週12小時。
※敬請留意:課程日期原定5/30、6/6(六)上課,因故異動至7/26(日)開課, 敬請見諒。謝謝~
※敬請留意:課程日期原定5/30、6/6(六)上課,因故異動至7/26(日)開課, 敬請見諒。謝謝~
上課時數:
12 小時
上課地點:
網路線上
課程費用:
(以下費用已由竹科管理局補助80%)
5000元
(科學園區廠商優惠價格需送出報名表後,系統發出報名成功回函確認金額。)
超值優惠:
課程目標:
1️⃣協助具Python程式語言基礎之學員學會運用PyTorch此深度學習框架開發深度學習模型,尤其是生成式對抗網路,擴散模型以及視覺語言模型。
2️⃣未來可銜接各類進階深度學習模型開發課程。
3️⃣學會如何運用Stable Diffusion產生我們心目中的那張”圖”!
4️⃣學會如何運用開源模型開發各類視覺語言模模型應用。
2️⃣未來可銜接各類進階深度學習模型開發課程。
3️⃣學會如何運用Stable Diffusion產生我們心目中的那張”圖”!
4️⃣學會如何運用開源模型開發各類視覺語言模模型應用。
課程特色:
1️⃣ 生成式影像模型為核心:
(1)涵蓋 GAN 的完整演進
從 Ian Goodfellow 的初代 GAN、DCGAN、Pix2Pix、CycleGAN 到 StarGAN,完整學習生成式對抗網路的理論與實作。
(2)影像生成與轉換能力
-StyleGAN:生成高真實度人臉 -StarGAN:同一模型可改變人臉屬性(年齡、髮型、膚色)
-AugGAN / CycleGAN:場景轉換(白天/夜晚、馬變斑馬)
-DeepFake 應用:生成技術進入極高擬真層次
(3)Diffusion Model 技術引入
-透過逐步加噪/去噪生成高品質影像
-Stable Diffusion 利用潛空間(Latent Space)減少運算量,讓個人電腦也可高效生成影像
2️⃣ 高階影像微調與控制技術
-ControlNet:精準控制影像姿態、邊緣與深度資訊
-DreamBooth:學習特定人物、物件或風格,無需重訓整個模型
-LoRA (Low-Rank Adaptation):輕量化微調特定風格
-Textual Inversion:學習新詞彙或抽象概念,生成個人化影像
-Instruct-Pix2Pix:結合 GPT 指令理解能力,用自然語言修改影像
3️⃣ 視覺語言模型 (VLM) 與多模態理解
-CLIP:圖文對齊,實現零樣本分類 (Zero-shot classification)
-BLIP / BLIP2:圖像描述(Captioning)、視覺問答(VQA)
-LLaVA:多模態對話式應用,可「看圖聊天」、推論影像語意
-GPT-4V:進階多模態理解,可讀取螢幕截圖、文件、圖表與照片,模糊文字與影像界線
4️⃣ 實作導向、PyTorch 深度學習框架
(1)從基礎理論到完整模型實作:
-手寫數字影像生成 (初代 GAN)
-人臉生成 (DCGAN)
-成對與非成對影像轉換 (Pix2Pix、CycleGAN)
-擴散模型實作與微調(DreamBooth、LoRA、Textual Inversion)
-視覺語言模型實作(CLIP、BLIP2、LLaVA)
(2)強調從理論 → 實作 → 應用,讓學員能自己開發多模態 AI 專案
5️⃣ 課程目標與學習成果
-學會 GAN、Diffusion、VLM 的原理與實作
-運用 Stable Diffusion 與開源模型生成個人化影像
-掌握多模態 AI 技術,能實現 圖像生成、轉換、描述、視覺問答
-為進階深度學習模型開發或 AI 創意應用奠定基礎
(1)涵蓋 GAN 的完整演進
從 Ian Goodfellow 的初代 GAN、DCGAN、Pix2Pix、CycleGAN 到 StarGAN,完整學習生成式對抗網路的理論與實作。
(2)影像生成與轉換能力
-StyleGAN:生成高真實度人臉 -StarGAN:同一模型可改變人臉屬性(年齡、髮型、膚色)
-AugGAN / CycleGAN:場景轉換(白天/夜晚、馬變斑馬)
-DeepFake 應用:生成技術進入極高擬真層次
(3)Diffusion Model 技術引入
-透過逐步加噪/去噪生成高品質影像
-Stable Diffusion 利用潛空間(Latent Space)減少運算量,讓個人電腦也可高效生成影像
2️⃣ 高階影像微調與控制技術
-ControlNet:精準控制影像姿態、邊緣與深度資訊
-DreamBooth:學習特定人物、物件或風格,無需重訓整個模型
-LoRA (Low-Rank Adaptation):輕量化微調特定風格
-Textual Inversion:學習新詞彙或抽象概念,生成個人化影像
-Instruct-Pix2Pix:結合 GPT 指令理解能力,用自然語言修改影像
3️⃣ 視覺語言模型 (VLM) 與多模態理解
-CLIP:圖文對齊,實現零樣本分類 (Zero-shot classification)
-BLIP / BLIP2:圖像描述(Captioning)、視覺問答(VQA)
-LLaVA:多模態對話式應用,可「看圖聊天」、推論影像語意
-GPT-4V:進階多模態理解,可讀取螢幕截圖、文件、圖表與照片,模糊文字與影像界線
4️⃣ 實作導向、PyTorch 深度學習框架
(1)從基礎理論到完整模型實作:
-手寫數字影像生成 (初代 GAN)
-人臉生成 (DCGAN)
-成對與非成對影像轉換 (Pix2Pix、CycleGAN)
-擴散模型實作與微調(DreamBooth、LoRA、Textual Inversion)
-視覺語言模型實作(CLIP、BLIP2、LLaVA)
(2)強調從理論 → 實作 → 應用,讓學員能自己開發多模態 AI 專案
5️⃣ 課程目標與學習成果
-學會 GAN、Diffusion、VLM 的原理與實作
-運用 Stable Diffusion 與開源模型生成個人化影像
-掌握多模態 AI 技術,能實現 圖像生成、轉換、描述、視覺問答
-為進階深度學習模型開發或 AI 創意應用奠定基礎
修課條件:
具備機器學習基礎知識、以及基礎Python程式開發經驗。
課程大綱:
1. 生成式對抗網路原理以及量化指標
2. 手寫數字影像生成:運用Ian Goodfellow所提出的初代GAN實現手寫數字生成。
2. 基礎人臉影像生成: 運用DCGAN實現人臉影像生成(使用CelebA dataset)。
3. 成對影像轉換:運用Pix2pix模型實現建築物影像轉換:給定建築物外觀草圖,將這些草圖轉換為真實的建築物外觀。
4. 非成對影像轉換: 運用能從非成對影像中學習的CycleGAN實現馬變斑馬。
5. 日夜街景影像轉換:運用CycleGAN加上Cycle-Object Edge Consistency將白天街景轉為夜晚。8. 擴散模型基本原理
9. 運用(使用CelebA dataset)
10 運用Dreambooth產生特定物品/動物在各種情境下的影像
11. 使用LORA產生特定風格(例如cyberpunk)的影像
12. 使用Textual Inversion產生特定物品/動物在各種情境下的影像
13. 使用Instruct-Pix2Pix修改一張圖片的內容,例如將照片中的人物變成機器人
14. Vision-Language Models (VLM) 理論與應用:介紹 CLIP 的圖文對齊原理,進行零樣本分類與圖文檢索。
15. BLIP2 / LLaVA 多模態生成實作: 透過 BLIP2 實現圖像描述 (Captioning),使用 LLaVA 進行視覺問答 (VQA)
2. 手寫數字影像生成:運用Ian Goodfellow所提出的初代GAN實現手寫數字生成。
2. 基礎人臉影像生成: 運用DCGAN實現人臉影像生成(使用CelebA dataset)。
3. 成對影像轉換:運用Pix2pix模型實現建築物影像轉換:給定建築物外觀草圖,將這些草圖轉換為真實的建築物外觀。
4. 非成對影像轉換: 運用能從非成對影像中學習的CycleGAN實現馬變斑馬。
5. 日夜街景影像轉換:運用CycleGAN加上Cycle-Object Edge Consistency將白天街景轉為夜晚。8. 擴散模型基本原理
9. 運用(使用CelebA dataset)
10 運用Dreambooth產生特定物品/動物在各種情境下的影像
11. 使用LORA產生特定風格(例如cyberpunk)的影像
12. 使用Textual Inversion產生特定物品/動物在各種情境下的影像
13. 使用Instruct-Pix2Pix修改一張圖片的內容,例如將照片中的人物變成機器人
14. Vision-Language Models (VLM) 理論與應用:介紹 CLIP 的圖文對齊原理,進行零樣本分類與圖文檢索。
15. BLIP2 / LLaVA 多模態生成實作: 透過 BLIP2 實現圖像描述 (Captioning),使用 LLaVA 進行視覺問答 (VQA)
課程師資:
自強基金會 林老師
現任瑞典Chalmers University of Technology博士後研究員
經歷
▻ 工研院機械所副研究員/研究員/資深研究員
▻ 馬來西亞偉特科技公司(ViTrox)研發顧問
▻ 馬來西亞10 EPOCH科技公司研發顧問
▻ 加州大學聖塔芭芭拉分校資工系訪問研究員
專長
電腦視覺、機器學習、深度學習及其在駕駛輔助系統以及自駕車之各種應用
現任瑞典Chalmers University of Technology博士後研究員
經歷
▻ 工研院機械所副研究員/研究員/資深研究員
▻ 馬來西亞偉特科技公司(ViTrox)研發顧問
▻ 馬來西亞10 EPOCH科技公司研發顧問
▻ 加州大學聖塔芭芭拉分校資工系訪問研究員
專長
電腦視覺、機器學習、深度學習及其在駕駛輔助系統以及自駕車之各種應用
主辦單位:
財團法人自強工業科學基金會
相關課程:
🏆 8-9月科管局補助【實體課程】🏆
15W330『影像人機介面技術:OpenCV 與 AI 影像辨識實戰課程(實作)』(8/16開班)
15W332『用 Flowise 快速打造第一個 AI 助理:新手也能做的 RAG × API 實戰(實作) 』(8/30開班)
15W331『用 n8n 打造企業級自動化系統:API × AI × 工作流程整合實戰班(實作)』(9/13開班)
15W328『CUDA-GPU程式設計及優化實作 (實作)』(9/16開班)
🏆 8-10月科管局補助【線上課程】🏆
15W334『掌握 LangGraph 與新世代Agentic AI 技術(實作) 』(8/1開班)
15W335『AI Coding 實戰入門:用 Cursor 2.0實現AI代理人開發和設計UI/UX介面一站搞定』(8/15開班)
15W336『Google AI 生態全攻略:Multi-Agent系統開發實戰』(8/29開班)
15W337『Claude Code & Agentic RAG 實戰:打造工業級自主開發系統與企業知識庫』(9/12開班)
15W318『資料視覺化與特徵工程(實作)』 (9/4開班)
15W324『PyTorch深度學習瑕疵檢測於智慧製造之應用』(10/4開班)
15W319『資料與智慧決策實戰(實作)』 (10/6開班)
15W330『影像人機介面技術:OpenCV 與 AI 影像辨識實戰課程(實作)』(8/16開班)
15W332『用 Flowise 快速打造第一個 AI 助理:新手也能做的 RAG × API 實戰(實作) 』(8/30開班)
15W331『用 n8n 打造企業級自動化系統:API × AI × 工作流程整合實戰班(實作)』(9/13開班)
15W328『CUDA-GPU程式設計及優化實作 (實作)』(9/16開班)
🏆 8-10月科管局補助【線上課程】🏆
15W334『掌握 LangGraph 與新世代Agentic AI 技術(實作) 』(8/1開班)
15W335『AI Coding 實戰入門:用 Cursor 2.0實現AI代理人開發和設計UI/UX介面一站搞定』(8/15開班)
15W336『Google AI 生態全攻略:Multi-Agent系統開發實戰』(8/29開班)
15W337『Claude Code & Agentic RAG 實戰:打造工業級自主開發系統與企業知識庫』(9/12開班)
15W318『資料視覺化與特徵工程(實作)』 (9/4開班)
15W324『PyTorch深度學習瑕疵檢測於智慧製造之應用』(10/4開班)
15W319『資料與智慧決策實戰(實作)』 (10/6開班)
學員須知:
證書及上課證明發放規定:
注意事項
※請前往竹科管理局廠商與單位名錄進行查詢,即可判斷公司是否為園區內廠商。
- 本計畫鼓勵女性學員報名參加培訓課程,必要時得優先錄取。
- 本計畫以竹科園區事業單位從業員工為主優先錄取,若有名額將開放有志進入園區就業人士報名參加。
- 請學員填寫能收到紙本講義之有效地址(提供地址錯誤將不重寄紙本講義),已有提供電子講義下載之課程/講座將不另郵寄紙本講義。
- 若遇不可預測之突發因素,基金會保有相關課程調整、取消及講師之變動權。
- 無紙化環境,輕鬆達到減碳救地球,即日起16小時以上課程結業證書或未達16小時課程上課證明皆以電子方式提供。
- 本課程不適用廠商VIP折扣優惠
- 課前請詳閱簡章之課程內容或利用課程諮詢電話。
- 課程嚴禁旁聽,亦不可攜眷參與。
- 優惠方案擇一使用。
📌課程費用包含:講義及稅。《不提供午餐》
📌計畫補助課程不適用於其他基金會優惠方案及不可使用紅利點數折抵費用。
📌計畫補助課程《確定開課》/《線上課程講義寄出》後,若因故無法上課,則不予退費。
🔥🔥《企業內訓應援》
歡迎填寫🎯訓練心願清單《請點🎯》 !
我們將根據您的回饋來設計具體可行的課程方案,
是您達成培訓目標最強有力的後盾!😊